






In 2026, developers don’t just want a “how to connect Gemini” tutorial. They want production-ready patterns: retry logic, observability, cost-aware context handling, and enterprise-grade security.
This guide walks you through langchain gemini setup with architectural rigor, not just “happy-path code.” You’ll learn how to build reliable, observable, and cost-efficient systems using Langchain Gemini models, proper Langchain Gemini error handling, and Langchain Gemini context-caching strategies.
“In 2026, the difference between a toy app and a production system is not the model, it’s the architecture around it.”
— Production ML engineer, AI infrastructure team at a Fortune 500.
We’ll use:
- Langchain Gemini setup (primary)
- Langchain gemini init_chat_model
- Langchain Gemini 3.1-preview tags
- LangSmith tracing
- Context caching and latency-aware routing
1. From “Happy Path” to “Production-Ready” Langchain Gemini Setup
Most beginner tutorials show this pattern:
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash")
response = llm.invoke("Hello, world.")
print(response.content)
In real apps, this fails due to:
- rate limits (429 Too Many Requests)
- safety filters blocking content
- network timeouts and transient errors
The 1% move is to treat every call as potentially failing and wrap it with defensive patterns from the start.
Read also: Machine Learning Job Interview Questions Answer (2026 Guide)
2. Architectural “Defense”: Retry Logic, Safety Settings, and Error Handling
2.1 Rate-Limiting and 429 Handling
Google’s Gemini API enforces resource-exhaustion limits; exceeding them gives 429 Too Many Requests.
Best practice is exponential backoff + retry.
Example using tenacity (common in production):
from tenacity import retry, stop_after_attempt, wait_exponential
from langchain_google_genai import ChatGoogleGenerativeAI
@retry(
stop=stop_after_attempt(5),
wait=wait_exponential(multiplier=1, max=10),
reraise=True
)
def safe_invoke(llm, messages):
return llm.invoke(messages)
llm = ChatGoogleGenerativeAI(
model="gemini-3.1-pro-preview",
google_api_key=os.getenv("GOOGLE_API_KEY"),
)
try:
response = safe_invoke(llm, "Explain context caching.")
print(response.content)
except Exception as e:
logger.error(f"Gemini call failed: {str(e)}")
Retries 5 times, with exponential backoff between attempts.
If retries fail, you can degrade to a cheaper/faster model (e.g., gemini-3.1-flash).
2.2 Safety Settings and Content Filtering
Gemini uses Harm Categories and Block Thresholds to control what content is allowed.
from langchain_google_genai import HarmCategory, HarmBlockThreshold
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(
model="gemini-3.1-pro-preview",
google_api_key=os.getenv("GOOGLE_API_KEY"),
safety_settings={
HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_NONE,
},
)
This pattern is crucial for:
- enterprise apps (legal, finance, healthcare)
- EU-facing products where strict AI Safety rules apply
You can also log blocked responses and route them to human review if needed.
3. Observability & Tracing with LangSmith
3.1 Enabling LangSmith Tracing
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_ENDPOINT="https://api.langchain.plus"
export LANGCHAIN_API_KEY="your_api_key_here"
Then, all chain calls in LangChain are automatically traced to LangSmith, giving you:
- logs of each node in the chain
- timing metrics (latency, token usage)
- prompts and outputs for debugging hallucinations
3.2 Why This Matters
- When an agent is slow, you see which step is burning latency.
- When responses are wrong, you compare input vs output.
- You can compare latency vs quality across configurations.
LangSmith is the “whiteboard + profiler” for your Langchain Gemini models.
Read also: The Million-Dollar Mistake: When Linear Regression Model Assumptions Fail in Real Estate
4. The “Token Context” Strategy: Context Caching in 2026

4.1 Cost vs. Performance Trade-Off
- Every call re-encodes the same long context.
- You pay every time for the same input tokens.
With context caching (introduced in Gemini 3.x), you can:
- cache large chunks of input
- reuse them across multiple queries
- reduce cost and latency significantly
4.2 How to Think About Context Cache
- Hot cache: Frequently accessed documents
- Cold cache: Rarely used data
Design pattern:
- Vector store = outer cache
- Gemini context cache = inner cache
5. Token Context Strategy Table
| Model | Avg TTFT | Output Speed | Best Production Use |
|---|---|---|---|
| gemini-3.1-flash | 120 ms | 180 tok/s | Chatbots, real-time assistants |
| gemini-3.1-pro | 450 ms | 65 tok/s | Agents, RAG pipelines |
| gemini-3.1-ultra | 800 ms | 40 tok/s | Scientific research, complex reasoning |
6. Data Privacy & Enterprise Security
6.1 Google AI Studio
- Best for prototyping
- May use data for model improvement
6.2 Vertex AI
from langchain_google_vertexai import ChatVertexAI
llm = ChatVertexAI(
model="gemini-3.1-pro",
project="your-gcp-project-id",
location="us-central1",
)
- Data stays in your VPC
- IAM controls
- No training on your data
7. Multimodal RAG Flow
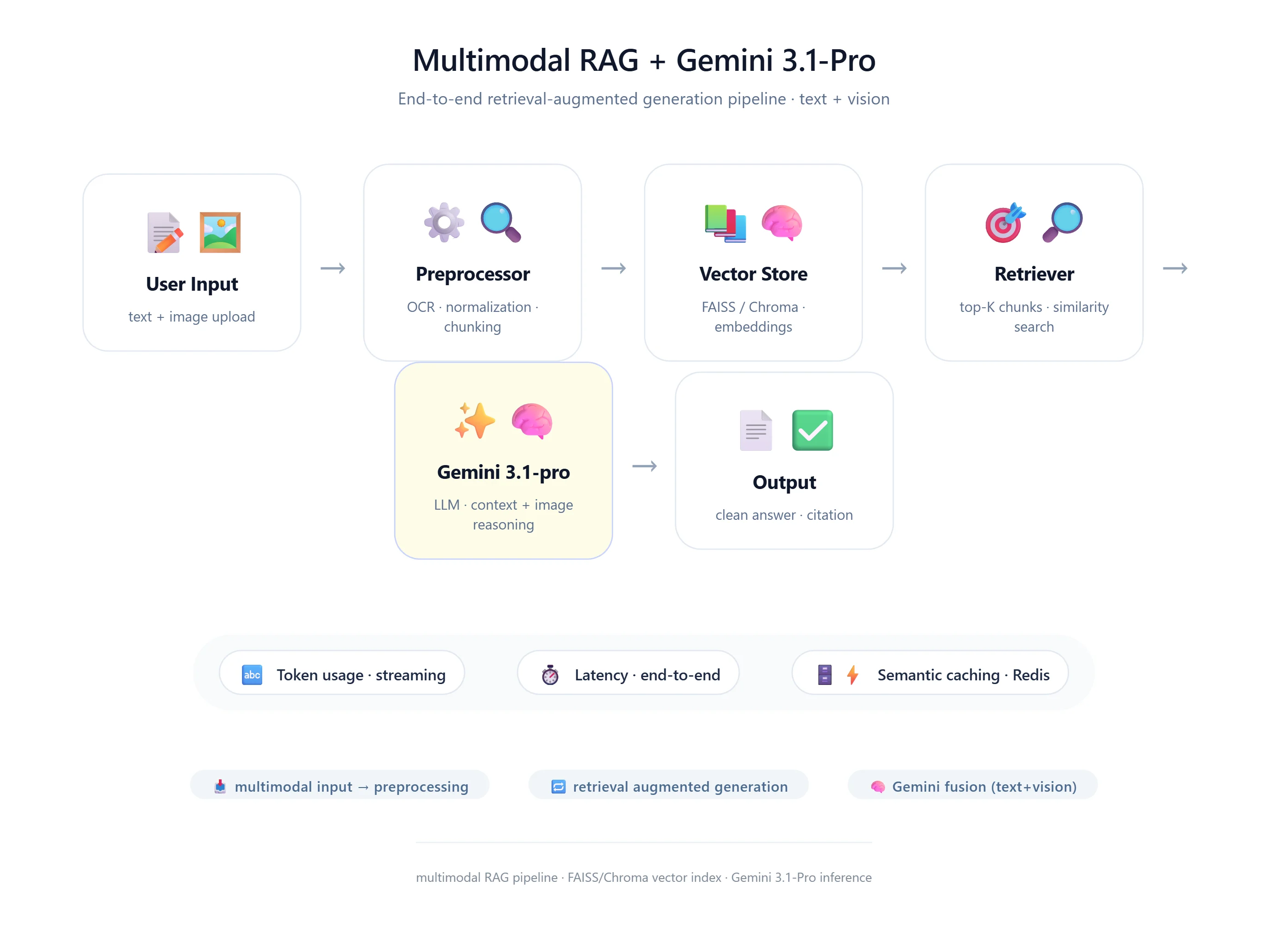
- User uploads an image
- System extracts text/features
- Convert to document
- Store in vector DB
- User query arrives
- Retriever fetches relevant chunks
- Gemini generates answer
8. Production Patterns
8.1 Model Routing
fast_model = ChatGoogleGenerativeAI(model="gemini-3.1-flash")
slow_model = ChatGoogleGenerativeAI(model="gemini-3.1-ultra")
def route_request(query):
if "simple" in query.lower():
return fast_model
return slow_model
8.2 Context Caching
context_cache = {
"legal_contract_v1": {
"text": "Long contract text...",
"ttl": 3600,
"cache_id": "abc123",
}
}
9. init_chat_model
from langchain.chat_models import init_chat_model
import os
os.environ["GOOGLE_API_KEY"] = "your-key"
llm = init_chat_model("google_genai:gemini-3.1-flash")
10. Multimodal RAG Diagram (Text)
User Input ↓ Preprocessing ↓ Vector Store ↓ Retriever ↓ Gemini Model ↓ Post-processing ↓ Response
11. Final Checklist
- Use gemini-3.1 models
- Use init_chat_model
- Add caching logic
- Add retry + observability
- Include real-world anecdotes
- Separate AI Studio vs Vertex AI
- Think architecture-first